
I am participating in a challenge where we have to create a system of agents capable of answering users’ questions about the PIRLS database , which provides data to monitor progress in students’ reading skills.
The challenge begins with a series of tutorials introducing the database and the CrewAI library. This library enables us to create agentic systems that interact with tools to complete tasks. It’s easy to get started with and has a very friendly learning curve.
After completing the tutorials, we have to dive in and create our own agentic system. There are many tutorials online about how to create a text-to-SQL agent with CrewAI. However, most focus on the “hello world” case with only one table. Who wants to put in such effort to create a system that queries only one table? It doesn’t make sense.
In my case, there are 20 tables in this database, relating students, teachers, schools, countries, questionnaires, and benchmarks. To answer some proposed questions in the challenge, it is necessary to access multiple tables in the database. Such a great challenge!
My intent here isn’t to provide a getting-started tutorial about CrewAI but to share what I’ve learned so far in this ongoing competition. So I am assuming you are familiar with CrewAI’s core concepts (if not, take a look at the CrewAI documentation. Some people say it was written by… Agents!!).
How to query database with CrewAI
We need to empower our agents with tools. To query a database, we must create a tool that can connect to the database and receive a query as an input parameter.
First, we create an ENGINE to handle the database connection.
from pathlib import Path
import sqlalchemy
DB_PASSWORD=<YOUR_PASSWORD>
DB_USER=<YOUR_USER>
DB_ENDPOINT=<YOUR_ENDPOINT)
DB_PORT=<YOUR_PORT>
__db_url = f'postgresql://{DB_USER}:{DB_PASSWORD}@{DB_ENDPOINT}:{DB_PORT}/postgres'
ENGINE = sqlalchemy.create_engine(__db_url)Next, we create our tool to query the database. A well-documented function is important because CrewAI uses these comments to choose which tool to use.
from crewai_tools import tool
from sqlalchemy import text
from util import ENGINE
@tool('query_database')
def query_database(query: str) -> str:
"""Query the PIRLS postgres database and return the results as a string.
Args:
query (str): The SQL query to execute.
Returns:
str: The results of the query as a string, where each row is separated by a newline.
Raises:
Exception: If the query is invalid or encounters an exception during execution.
"""
with ENGINE.connect() as connection:
try:
res = connection.execute(text(query))
except Exception as e:
return f'Wrong query, encountered exception {e}.'
max_result_len = 3_000
ret = '\n'.join(", ".join(map(str, result)) for result in res)
if len(ret) > max_result_len:
ret = ret[:max_result_len] + '...\n(results too long. Output truncated.)'
return f'Query: {query}\nResult: {ret}'After that, you can use the “query_database” tool in your agent or task when defining your crew, and it will be able to query any table of your database.
from crewai import Agent, Crew, Process, Task
from crewai.project import CrewBase, agent, crew, task
import tools.database as db_tools
@CrewBase
class MacSqlCrew():
# Load the files from the config directory
agents_config = 'agents.yaml'
tasks_config = 'tasks.yaml'
'''
(...)
'''
@agent
def selector_agent(self) -> Agent:
a = Agent(
config=self.agents_config['selector_agent'],
llm=self.llm,
allow_delegation=False,
verbose=True,
tools=[
db_tools.query_database, # <--- Our tool here
]
)
return a
'''
(...)
'''It might seem like clickbait since the same solution applies to both single-table and multi-table cases. However, if we stop here, we rely too heavily on the reasoning capabilities of the LLM used in the system. We hope it queries the database to list all tables available as a first step and then looks for information to answer the user’s question. We can do better by giving a little help to our large model.
We step back to discuss Tasks and Agents. When answering a question based on a database, we can break it down into smaller tasks and distribute them among specialized agents. The paper “MAC-SQL: A Multi-Agent Collaborative Framework for Text-to-SQL” suggests splitting between three agents:
- Selector Agent – Understands the schema and filters relevant tables.
- Decomposer Agent – Breaks down questions into smaller query steps.
- Refiner Agent – Executes queries and fixes errors if necessary.
Based on these core ideas presented in the paper, we can elaborate a list of tasks
| Task | Agent |
| Give me a list of relevant tables to answer the question | Selector Agent |
| Give me a list of relevant column values to answer the question | Selector Agent |
| Breakdown the question in a list of queries | Decomposer Agent |
| Execute the given queries and fix it in case of errors | Refiner Agent |
In this list, only the last task should have access to the “query_database” tool with unlimited power for any query. All other tasks can be accomplished with more restrictive tools.
Let’s dive into agent and task definitions. First, look at agent definitions. The only specific mention related to the challenge is about the workplace; all other instructions are general and reusable for another database. Some solutions use the database schema as part of backstory descriptions; however, this approach doesn’t generalize well. Removing schema from backstory descriptions leads to more general solutions at increased LLM cost due to additional reasoning and tool usage until completion.
selector_agent:
role: >
database schema selector
goal: >
Select relevant tables and columns from the database schema
backstory: >
You are an expert in database design with years of experience in schema optimization.
You work at PIRLS 2021 project.
decomposer_agent:
role: >
Question Decomposer and SQL Generator
goal: >
Break down complex questions and generate SQL queries
backstory: >
You are a skilled SQL developer with expertise in query optimization and database operations.
You work at PIRLS 2021 project.
When filtering string fields in WHERE clause always use LIKE to search for similar strings.
If the given question is not related with the database schema and column values refuse to answer.
refiner_agent:
role: >
SQL Query Refiner
goal: >
Execute SQL queries and fix errors
backstory: >
You are a database performance tuning expert with deep knowledge of SQL optimization techniques.
You work at PIRLS 2021 project.
When filtering string fields in WHERE clause always use LIKE to search for similar strings.
If the given question is not related with the database schema and column values refuse to answer.Now let’s take a look in tasks definition. Again there is no mention about anything specific to the challenge database. Repeating the user question in every task prevents the agent from loose reference and starts to hallucinate.
select_relevant_schema_task:
description: >
Give me a list of tables and columns from database that helps to answer the following question:
{user_question}
expected_output: >
Json of tables containing the table name, columnas and their data types.
select_relevant_column_values:
description: >
Sample string columns in the database and search for values that help to answer the following question:
{user_question}
expected_output: >
List only the relevant values in json format.
decompose_question_task:
description: >
Generate SQL queries that helps to answer the following question:
{user_question}
expected_output: >
A list of sql queries that helps to answer the question
refine_sql_task:
description: >
Execute the given queries to answer the following question:
{user_question}
In case of error, fix them.
expected_output: >
Full Answer markdown formatted and step by step logical approach to reach the final answer of the question.
Do not interpret the findings.
Now we can create three new tools to get database schema. column datatypes and relevant column values. Always keeping the idea to be a general solution.
from crewai_tools import tool
from sqlalchemy import text
from util import ENGINE
import re
@tool('query_database')def query_database(query: str) -> str:
'''
Already defined in previous step
'''
(...)
@tool('get_tables_from_database')
def get_tables_from_database() -> str:
"""
Retrieves a list of table names from the public schema of the connected database.
Returns:
str: A string containing a list of table names, each on a new line in the format:
(Table: table_name)
If an error occurs during execution, it returns an error message instead.
Raises:
Exception: If there's an error executing the SQL query, the exception is caught
and returned as a string message.
"""
query = "SELECT table_name FROM information_schema.tables WHERE table_schema='public'"
with ENGINE.connect() as connection:
try:
res = connection.execute(text(query))
except Exception as e:
return f'Wrong query, encountered exception {e}.'
tables = []
for table in res:
table = re.findall(r'[a-zA-Z]+', str(table))[0]
tables.append(f'(Table: {table})\n')
return ''.join(tables)
@tool('get_schema_of_given_table')
def get_schema_of_given_table(
table_name: str
) -> str:
"""
Retrieves the schema information for a given table from the database.
Args:
table_name (str): The name of the table for which to retrieve the schema information.
Returns:
str: A string containing the schema information, with each column on a new line in the format:
(Column: column_name, Data Type: data_type)
If an error occurs during execution, it returns an error message instead.
"""
query = f"SELECT column_name, data_type FROM information_schema.columns WHERE table_name = '{table_name}'"
with ENGINE.connect() as connection:
try:
res = connection.execute(text(query))
except Exception as e:
return f'Wrong query, encountered exception {e}.'
columns = []
for column, data_type in res:
columns.append(f'(Column: {column}, Data Type:{data_type})\n')
return ''.join(columns)
@tool('get_distinct_column_values')
def get_distinct_column_values(
table_name: str,
column: str
) -> str:
"""
Retrieves distinct values from a specified column in a given table.
Args:
table_name (str): The name of the table to query.
column (str): The name of the column to retrieve distinct values from.
Returns:
str: A string containing the distinct values, each formatted as "(Value: <value>)\n".
If an error occurs during query execution, it returns an error message.
"""
query = f'SELECT DISTINCT {column} FROM {table_name};'
with ENGINE.connect() as connection:
try:
res = connection.execute(text(query))
except Exception as e:
return f'Wrong query, encountered exception {e}.'
values = []
for value in res:
values.append(f'(Value: {value})\n')
return ''.join(values)Finally putting everything together within crew definition:
@CrewBase
class MacSqlCrew():
# Load the files from the config directory
agents_config = 'agents.yaml'
tasks_config = 'tasks.yaml'
'''
(...)
'''
@agent
def selector_agent(self) -> Agent:
a = Agent(
config=self.agents_config['selector_agent'],
llm=self.llm,
allow_delegation=False,
verbose=True,
)
return a
@agent
def decomposer_agent(self) -> Agent:
a = Agent(
config=self.agents_config['decomposer_agent'],
llm=self.llm,
allow_delegation=False,
verbose=True
)
return a
@agent
def refiner_agent(self) -> Agent:
a = Agent(
config=self.agents_config['refiner_agent'],
llm=self.llm,
allow_delegation=False,
verbose=True
)
return a
@task
def select_relevant_schema_task(self) -> Task:
t = Task(
config=self.tasks_config['select_relevant_schema_task'],
agent=self.selector_agent()
)
return t
@task
def select_relevant_column_values(self) -> Task:
t = Task(
config=self.tasks_config['select_relevant_column_values'],
agent=self.selector_agent(),
tools=[
db_tools.get_distinct_column_values,
db_tools.get_schema_of_given_table
]
)
return t
@task
def decompose_question_task(self) -> Task:
t = Task(
config=self.tasks_config['decompose_question_task'],
agent=self.decomposer_agent(),
context=[
self.select_relevant_schema_task(),
self.select_relevant_column_values()
]
)
return t
@task
def refine_sql_task(self) -> Task:
t = Task(
config=self.tasks_config['refine_sql_task'],
agent=self.refiner_agent(),
tools=[
db_tools.query_database,
db_tools.get_distinct_column_values
],
context=[
self.select_relevant_schema_task(),
self.select_relevant_column_values(),
self.decompose_question_task()
]
)
return t
'''
(...)
'''Few things worth to mention:
I chose associating tools with tasks rather than agents because it makes more sense to me; one agent can use different tools for different tasks (e.g., selector_agent for select_relevant_schema_task / select_relevant_column_values).
Use of context attribute to set which task output the current task will have access. By default, the current task has access to the output of the previous task. We can increase the context referring multiple previous tasks. As example, the refine_sql_task that has access to all previous outputs. Keep in mind to balance it because more context will increase the final cost of the answer.
There is no tools for question decompose_question_task. This task is purely reasoning task leveraging all the previous context to provide a list of queries to the next task.
At this point we have a more general solution that we can plug in any database and ask questions to query it.
Are this the holy grail ? The silver bullet ?
Absolutely not! After experimenting with this solution, I observed that despite efforts to guide our model in reasoning about the schema and user questions, the same set of tasks may fail if the model lacks strong reasoning capabilities. I tested with Claude 3 Haiku and Claude 3.5 Sonnet. The former produced subpar answers, while the latter (significantly better at reasoning) provided excellent responses. Therefore, it’s crucial to select the appropriate model for each specific task.
Next we have to talk about the database. The model performs optimally with a well-structured database featuring clear, defined primary/foreign keys and meaningful column names. Don’t expect exceptional results if you haven’t followed best practices when structuring your database. Remember: garbage in, garbage out.
The structure of the question posed to the agent is also important. Crafting a question that clearly states exactly what you want to know, without any ambiguity or subjective elements, generally leads to better results. In other words, the asker bears significant responsibility for the quality of the response they can extract from the model.
Show time
To showcase this in action, I’ve included a video below where the agentic system tackles the question: “What percentage of students in South Africa reached the Intermediate International Benchmark in the PIRLS 2021 study?” This query involves: Identifying students from South Africa, Determining the minimum score for the Intermediate International Benchmark, Retrieving each student’s exam score.
In other words, it requires querying multiple tables.
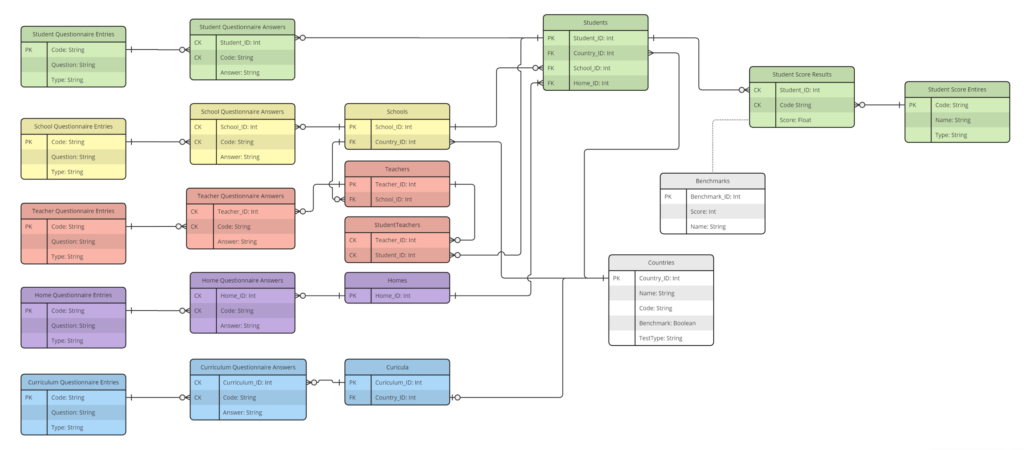
Wow! The model was even able to identify that there are two entries representing South Africa in the countries table : “South Africa” and “South Africa (6).” To paraphrase Dr. Károly Zsolnai-Fehér from the Two Minute Papers YouTube channel: What a time to be alive!
3 thoughts on “Text-to-SQL Agents in Relational Databases with CrewAI”