
Continuing my participation in the GDSC7 challenge introduced in this post I’ve noticed that the organizers are focusing more on the experimental aspects of agent systems. This prompted me to consider ways to reduce API usage costs while maintaining answer quality.
Observing the public set of questions that the system is tested against I came across with a case that I could abstract to a more general problem. Take a look at the two following questions:
- “Are boys or girls most lagging behind in reading abilities?”
- “Does the gender of a child have an impact on the reading capabilities of 4th graders?”
Both questions could be answered with the same set of database knowledge. The first one, caught my attention. Remember the database schema, We don’t have a explicit table column to identify boys and girls. Instead, we have a question about how the participant identifies themselves.
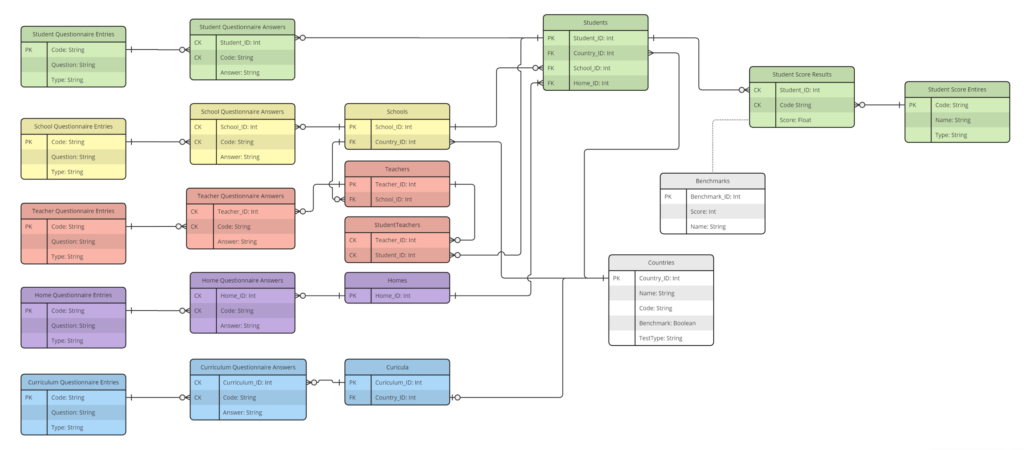
While testing my system locally I saw some models struggling to obtain the gender information. Some of them assumes, even knowing all the columns of the database, that exists a gender column in the Students table. Others, better at reasoning, have to explore the database making queries with the SQL LIKE instruction to find string values that identifies the gender. Now, imagine how many ways you have to store a identification of gender in a database. You can use: male-female, M-F, boys-girls, etc. In all the cases, even if the model figures out how the gender are stored in the database, it will result in a number of database calls and response analysis that could be avoided. Keep in mind that every database query response must be processed by the LLM and its reduction will directly reflect on the cost.
The solution is clear. We must use semantic search. All forms of gender identification should be close together in a embedding space.
Solution 1 – Embeddings for all string columns in the database
Analyzing the database we can see a pattern in questionnaire tables (all of them have a question columns). The same applies to the answer tables (all of them have a question column). We can leverage this information to create a general function to process questionnaire and answers. In addition to theses columns we have countries, benchmark names and student score names that are all string and can benefit from a semantic search.
Before creating the tools for the agent we have to create a vector database to store the embeddings and populate it.
Collection creation
I created a “rag” folder inside of the “src” folder and then created the “rag.py” file.
Next, I defined a main function to select distinct values of string column fields from the aforementioned tables. I am using chromadb package as the vector database and setting the path to “src/rag/collections” to persist the embeddings. To interact with the database I am using the “create_connection” and “get_from_db” functions made available by the competition organizers.
The chromadb package allows us to choose a Huggingface model as the embedding function. You have to pass you API key in the method. The API is free to use and you can create a specific key for this challenge.
def main():
PREFIX_LIST = ['student','school','teacher','home','curriculum']
connection = create_connection()
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collection = chroma_client.create_collection(name="countries", embedding_function=huggingface_ef, get_or_create=True)
query = ''' SELECT DISTINCT COUNTRY_ID, NAME FROM COUNTRIES '''
upsert_collection(connection, collection, query, 'name', 'country_id')
print(f'Countries collection size {collection.count()}')
collection = chroma_client.create_collection(name="benchmark", embedding_function=huggingface_ef, get_or_create=True)
query = ''' SELECT DISTINCT BENCHMARK_ID, NAME FROM BENCHMARKS '''
upsert_collection(connection, collection, query, 'name', 'benchmark_id')
print(f'Benchmarks collection size {collection.count()}')
collection = chroma_client.create_collection(name="studentscoreentries", embedding_function=huggingface_ef, get_or_create=True)
query = ''' SELECT DISTINCT CODE, NAME FROM STUDENTSCOREENTRIES '''
upsert_collection(connection, collection, query, 'name', 'code')
print(f'Student Score Entries collection size {collection.count()}')
''' questionnaire entries collections '''
for prefix in PREFIX_LIST:
collection_name = f'{prefix}questionnaireentries'
collection = chroma_client.create_collection(name=collection_name, embedding_function=huggingface_ef, get_or_create=True)
query = f''' SELECT DISTINCT CODE, QUESTION FROM {collection_name} '''
upsert_collection(connection, collection, query, 'question', 'code')
print(f'{prefix} questionnaire entries collection size {collection.count()}')
''' questionnaire answers collections '''
for prefix in PREFIX_LIST:
collection_name = f'{prefix}questionnaireanswers'
collection = chroma_client.create_collection(name=collection_name, embedding_function=huggingface_ef, get_or_create=True)
query = f''' SELECT DISTINCT ANSWER FROM {collection_name} ORDER BY 1 ASC '''
upsert_collection(connection, collection, query, 'answer' )
print(f'{prefix} questionnaire answers collection size {collection.count()}')The “upsert_collection” function was my attempt to generalize a function to store information in the vector database. It expects the database connection, the query, the field name of the relevant column and the field name for the primary key column. The answers tables have a composite primary key so I made a special treatment for these cases.
def upsert_collection(connection: psycopg2.extensions.connection, collection: chromadb.Collection, query: str, document_field: str, pk_field: str = None ):
query_df = get_from_db(connection, query)
documents_list = query_df[document_field].to_list()
if pk_field is not None:
ids_list = query_df[pk_field].astype(str).to_list()
metadata_list = [ { 'pk' : i , 'document_column_name': document_field, 'pk_colum_name': pk_field} for i in ids_list]
else:
ids_list = [str(i) for i in range(len(documents_list))]
metadata_list = [ { 'pk' : 'N/A' , 'document_column_name': document_field, 'pk_colum_name': 'N/A'} for i in ids_list]
try:
collection.upsert(
documents=documents_list,
ids=ids_list,
metadatas=metadata_list
)
except Exception as e:
print(e)Below is the full rag.py file.
import chromadb
import chromadb.utils.embedding_functions as embedding_functions
import os
import psycopg2 # module for connecting to a PostgreSQL database
import pandas as pd
import numpy as np
def create_connection() -> psycopg2.extensions.connection:
"""
Creates a connection to the PostgreSQL database. Uses the global variables DB_ENDPOINT, DB_PORT, DB_USER, DB_PASSWORD, DB_NAME.
Returns:
psycopg2.extensions.connection: A connection object to the PostgreSQL database.
"""
return psycopg2.connect(
host=os.environ['DB_ENDPOINT'],
port=os.environ['DB_PORT'],
user=os.environ['DB_USER'],
password=os.environ['DB_PASSWORD'],
database='postgres'
)
def get_from_db(connection: psycopg2.extensions.connection, query: str) -> pd.DataFrame:
"""
Executes the given SQL query on the provided database connection and returns the result as a pandas DataFrame.
Parameters:
connection (psycopg2.extensions.connection): The database connection object.
query (str): The SQL query to execute.
Returns:
pd.DataFrame: A pandas DataFrame containing the result of the query.
Raises:
psycopg2.Error: If there is an error executing the query.
"""
try:
with connection:
with connection.cursor() as cursor:
cursor.execute(query)
result = cursor.fetchall()
column_names = [desc[0] for desc in cursor.description]
except psycopg2.Error as e:
print(f"Error executing query: {e}")
return pd.DataFrame()
return pd.DataFrame(result, columns=column_names)
def upsert_collection(connection: psycopg2.extensions.connection, collection: chromadb.Collection, query: str, document_field: str, pk_field: str = None ):
query_df = get_from_db(connection, query)
documents_list = query_df[document_field].to_list()
if pk_field is not None:
ids_list = query_df[pk_field].astype(str).to_list()
metadata_list = [ { 'pk' : i , 'document_column_name': document_field, 'pk_colum_name': pk_field} for i in ids_list]
else:
ids_list = [str(i) for i in range(len(documents_list))]
metadata_list = [ { 'pk' : 'N/A' , 'document_column_name': document_field, 'pk_colum_name': 'N/A'} for i in ids_list]
try:
collection.upsert(
documents=documents_list,
ids=ids_list,
metadatas=metadata_list
)
except Exception as e:
print(e)
def main():
PREFIX_LIST = ['student','school','teacher','home','curriculum']
connection = create_connection()
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collection = chroma_client.create_collection(name="countries", embedding_function=huggingface_ef, get_or_create=True)
query = ''' SELECT DISTINCT COUNTRY_ID, NAME FROM COUNTRIES '''
upsert_collection(connection, collection, query, 'name', 'country_id')
print(f'Countries collection size {collection.count()}')
collection = chroma_client.create_collection(name="benchmark", embedding_function=huggingface_ef, get_or_create=True)
query = ''' SELECT DISTINCT BENCHMARK_ID, NAME FROM BENCHMARKS '''
upsert_collection(connection, collection, query, 'name', 'benchmark_id')
print(f'Benchmarks collection size {collection.count()}')
collection = chroma_client.create_collection(name="studentscoreentries", embedding_function=huggingface_ef, get_or_create=True)
query = ''' SELECT DISTINCT CODE, NAME FROM STUDENTSCOREENTRIES '''
upsert_collection(connection, collection, query, 'name', 'code')
print(f'Student Score Entries collection size {collection.count()}')
''' questionnaire entries collections '''
for prefix in PREFIX_LIST:
collection_name = f'{prefix}questionnaireentries'
collection = chroma_client.create_collection(name=collection_name, embedding_function=huggingface_ef, get_or_create=True)
query = f''' SELECT DISTINCT CODE, QUESTION FROM {collection_name} '''
upsert_collection(connection, collection, query, 'question', 'code')
print(f'{prefix} questionnaire entries collection size {collection.count()}')
''' questionnaire answers collections '''
for prefix in PREFIX_LIST:
collection_name = f'{prefix}questionnaireanswers'
collection = chroma_client.create_collection(name=collection_name, embedding_function=huggingface_ef, get_or_create=True)
query = f''' SELECT DISTINCT ANSWER FROM {collection_name} ORDER BY 1 ASC '''
upsert_collection(connection, collection, query, 'answer' )
print(f'{prefix} questionnaire answers collection size {collection.count()}')
if __name__ == "__main__":
main()We can execute this script to populate our vector database and move on to the next step: creating a tool to enhance our agents with semantic search.
Tool creation
You can create the new tool in the already existent file database.py (as I did ) or create a new file to store RAG related tools ( as I did too, after I enhanced my RAG systems with internet and Youtube video sources ). The tool selects the 5 suggestions, for each table, that come closest to the question in the embedding space. I created a structured output for the tool including the distance metric to help the model evaluate what are the most relevant results for the given question.
@tool('get_relevant_string_values')
def get_relevant_string_values(question: str):
"""
Retrieves relevant string values from multiple collections based on a given question.
Parameters:
question (str): The input question or query string used to find relevant values
Returns:
dict: A dictionary where each key is a collection name, and its value is another dictionary
containing the table name and a list of relevant values. Each relevant value is represented
as a dictionary with keys: 'primary_key_column_name', 'primary_key_column_value',
'relevant_column_name', 'relevant_column_value', and 'l2_distance'.
Example structure:
{
'collection_name': {
'table': 'collection_name',
'relevant_values': [
{
'primary_key_column_name': ...,
'primary_key_column_value': ...,
'relevant_column_name': ...,
'relevant_column_value': ...,
'l2_distance': ...
},
...
]
},
...
}
"""
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collections_list = [
'countries',
'benchmark',
'studentscoreentries',
'studentquestionnaireentries',
'schoolquestionnaireentries',
'teacherquestionnaireentries',
'homequestionnaireentries',
'curriculumquestionnaireentries',
'studentquestionnaireanswers',
'schoolquestionnaireanswers',
'teacherquestionnaireanswers',
'homequestionnaireanswers',
'curriculumquestionnaireanswers',
]
relevant_values_array = np.empty((0,6))
for collection_name in collections_list:
collection = chroma_client.get_collection(name=collection_name, embedding_function=huggingface_ef)
result = collection.query(
query_texts=[question],
n_results=5
)
document_list = result['documents'][0]
metadata_list = result['metadatas'][0]
distance_list = result['distances'][0]
pk_list = [i['pk'] for i in metadata_list ]
pk_colum_name_list = [i['pk_colum_name'] for i in metadata_list ]
document_column_name_list = [i['document_column_name'] for i in metadata_list ]
table_list = [collection_name for i in range(len(document_list))]
temp_array = np.column_stack((table_list, pk_colum_name_list , pk_list , document_column_name_list , document_list, distance_list))
relevant_values_array = np.concatenate(
(
relevant_values_array,
temp_array
),
axis = 0
)
df = pd.DataFrame( columns=['table','primary_key_column_name', 'primary_key_column_value', 'relevant_column_name','relevant_column_value','l2_distance'], data = relevant_values_array)
grouped = df.groupby('table')
# Construct the dictionary for each unique table
result = {}
for table_name, group in grouped:
result[table_name] = {
'table': table_name,
'relevant_values': group[['primary_key_column_name', 'primary_key_column_value', 'relevant_column_name','relevant_column_value','l2_distance']].to_dict(orient='records')
}
return resultNext, you just have to equip your agent with the new tool. That’s all you need to start doing semantic searches.
@agent
def data_engineer(self) -> Agent:
a = Agent(
config=self.agents_config['data_engineer'],
llm=self.llm,
allow_delegation=False,
verbose=True,
tools=[
db_tools.get_relevant_string_values,
db_tools.query_database
]
)
return aSolution 2- Embedding question and answers together
Looking closely at answer values, I started to see very short alternatives that does not have meaningful value alone. Samples like “A lot“, “Often” does not bring to much value without the question text. So I decided that another way to do a semantic search would be embedding the question and answers together as single text.
Collection creation
Below is the full rag.py file reviewed.
import chromadb
import chromadb.utils.embedding_functions as embedding_functions
import os
import psycopg2 # module for connecting to a PostgreSQL database
import pandas as pd
import numpy as np
def create_connection() -> psycopg2.extensions.connection:
"""
Creates a connection to the PostgreSQL database. Uses the global variables DB_ENDPOINT, DB_PORT, DB_USER, DB_PASSWORD, DB_NAME.
Returns:
psycopg2.extensions.connection: A connection object to the PostgreSQL database.
"""
return psycopg2.connect(
host=os.environ['DB_ENDPOINT'],
port=os.environ['DB_PORT'],
user=os.environ['DB_USER'],
password=os.environ['DB_PASSWORD'],
database='postgres'
)
def get_from_db(connection: psycopg2.extensions.connection, query: str) -> pd.DataFrame:
"""
Executes the given SQL query on the provided database connection and returns the result as a pandas DataFrame.
Parameters:
connection (psycopg2.extensions.connection): The database connection object.
query (str): The SQL query to execute.
Returns:
pd.DataFrame: A pandas DataFrame containing the result of the query.
Raises:
psycopg2.Error: If there is an error executing the query.
"""
try:
with connection:
with connection.cursor() as cursor:
cursor.execute(query)
result = cursor.fetchall()
column_names = [desc[0] for desc in cursor.description]
except psycopg2.Error as e:
print(f"Error executing query: {e}")
return pd.DataFrame()
return pd.DataFrame(result, columns=column_names)
def create_countries_collection(connection, chroma_client, embedding_function):
collection = chroma_client.create_collection(name="countries", embedding_function=embedding_function, get_or_create=True)
query = ''' SELECT DISTINCT COUNTRY_ID, NAME FROM COUNTRIES '''
query_df = get_from_db(connection, query)
documents_list = query_df['name'].to_list()
ids_list = query_df['country_id'].astype(str).to_list()
collection.upsert(
documents=documents_list,
ids=ids_list
)
print(f'Countries collection size {collection.count()}')
def create_benchmark_collection(connection, chroma_client, embedding_function):
collection = chroma_client.create_collection(name="benchmarks", embedding_function=embedding_function, get_or_create=True)
query = ''' SELECT DISTINCT BENCHMARK_ID, NAME FROM BENCHMARKS '''
query_df = get_from_db(connection, query)
documents_list = query_df['name'].to_list()
ids_list = query_df['benchmark_id'].astype(str).to_list()
collection.upsert(
documents=documents_list,
ids=ids_list
)
print(f'Benchmark collection size {collection.count()}')
def create_studentscoreentries_collection(connection, chroma_client, embedding_function):
collection = chroma_client.create_collection(name="studentscoreentries", embedding_function=embedding_function, get_or_create=True)
query = ''' SELECT DISTINCT CODE, NAME FROM STUDENTSCOREENTRIES '''
query_df = get_from_db(connection, query)
documents_list = query_df['name'].to_list()
ids_list = query_df['code'].astype(str).to_list()
collection.upsert(
documents=documents_list,
ids=ids_list
)
print(f'Student Score Entries collection size {collection.count()}')
def main():
PREFIX_LIST = ['student','school','teacher','home','curriculum']
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
connection = create_connection()
create_countries_collection(connection, chroma_client, huggingface_ef)
create_benchmark_collection(connection, chroma_client, huggingface_ef)
create_studentscoreentries_collection(connection, chroma_client, huggingface_ef)
''' questionnaire collections '''
for prefix in PREFIX_LIST:
collection_name = f'{prefix}questionnaire'
collection = chroma_client.create_collection(name=collection_name, embedding_function=huggingface_ef, get_or_create=True)
query = f'''
WITH DISTINCT_ANSWERS AS (SELECT DISTINCT SQA.CODE, SQA.ANSWER FROM {prefix}QUESTIONNAIREANSWERS AS SQA)
SELECT
DISTINCT
SQE.CODE,
SQE.QUESTION,
DA.ANSWER
FROM {prefix}QUESTIONNAIREENTRIES AS SQE
LEFT JOIN DISTINCT_ANSWERS AS DA
ON
SQE.CODE = DA.CODE
'''
query_df = get_from_db(connection, query)
# Grouping by 'code' and 'question', and concatenating answers
transformed_df = query_df.groupby(['code', 'question'])['answer'].apply(lambda x: ' '.join(f'{i+1}) {val}\n' for i, val in enumerate(x))).reset_index()
transformed_df['question and answers'] = transformed_df['question'] + '\n' + transformed_df['answer']
transformed_df['question and answers'] = transformed_df['question and answers'].str.replace("'", "''")
transformed_df[['code','question and answers']]
documents_list = transformed_df['question and answers'].to_list()
ids_list = transformed_df['code'].astype(str).to_list()
collection.upsert(
documents=documents_list,
ids=ids_list
)
print(f'{prefix} questionnaire collection size {collection.count()}')
if __name__ == "__main__":
main()Tool creation
The tool was reviewed as well. I abandoned the idea of one tool to search in all tables and created a tool to search in question/answer pairs and other tools to search in countries, benchmark and student score tables.
Below is the full implementation of the tool to search question answer pairs. I added a threshold to filter question and answer pairs based on distance in the embedding space.
@tool('get_relevant_questions')
def get_relevant_questions(question: str):
"""
Retrieves relevant questions from various questionnaire collections based on the input question.
Args:
question (str): The question string to query against the collections.
Returns:
dict: A dictionary where each key is a collection name and its value is a list of relevant questions
with their associated metadata (code, question_and_answers, l2_distance).
"""
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collections_list = [
'studentquestionnaire',
'schoolquestionnaire',
'teacherquestionnaire',
'homequestionnaire',
'curriculumquestionnaire',
]
relevant_values_array = np.empty((0,4))
for collection_name in collections_list:
collection = chroma_client.get_collection(name=collection_name, embedding_function=huggingface_ef)
result = collection.query(
query_texts=[question],
n_results=5
)
document_list = result['documents'][0]
ids_list = result['ids'][0]
distance_list = result['distances'][0]
questionnaire_list = [collection_name for i in range(len(document_list))]
temp_array = np.column_stack((questionnaire_list, ids_list , document_list , distance_list))
relevant_values_array = np.concatenate(
(
relevant_values_array,
temp_array
),
axis = 0
)
df = pd.DataFrame( columns=['questionnaire','code', 'question_and_answers','l2_distance'], data = relevant_values_array)
df['l2_distance'] = df['l2_distance'].astype(float)
df = df.loc[df['l2_distance'] <= 1.0]
grouped = df.groupby('questionnaire')
# Construct the dictionary for each unique table
result = {}
for questionnaire_name, group in grouped:
result[questionnaire_name] = {
'table_prefix': questionnaire_name,
'relevant_values': group[['code', 'question_and_answers', 'l2_distance']].to_dict(orient='records')
}
if len(result) == 0:
result[0] = "Nothing related to this query. Try others terms."
return resultBelow are the tools to search in the remaining tables.
@tool('get_relevant_countries')
def get_relevant_countries(question:str):
"""
Retrieves relevant country information based on a specific question related to the PIRLS 2021 study.
Args:
question (str): The question string to query against the 'countries' collection.
Returns:
list: A list of dictionaries, each containing 'country_id', 'name', and 'l2_distance' of relevant countries.
"""
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collection = chroma_client.get_collection(name='countries', embedding_function=huggingface_ef)
result = collection.query(
query_texts=question,
n_results=5
)
document_list = result['documents'][0]
ids_list = result['ids'][0]
distance_list = result['distances'][0]
relevant_values_array = np.column_stack((ids_list , document_list , distance_list))
df = pd.DataFrame( columns=['country_id', 'name' ,'l2_distance'], data = relevant_values_array)
result = df.to_dict(orient='records')
return result
@tool('get_relevant_benchmarks')
def get_relevant_benchmarks(question:str):
"""
Retrieves relevant benchmark information based on a specific question related to the PIRLS 2021 study.
Args:
question (str): The question string to query against the 'benchmarks' collection.
Returns:
list: A list of dictionaries, each containing 'benchmark_id', 'name', and 'l2_distance' of relevant benchmarks.
"""
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collection = chroma_client.get_collection(name='benchmarks', embedding_function=huggingface_ef)
result = collection.query(
query_texts=question,
n_results=5
)
document_list = result['documents'][0]
ids_list = result['ids'][0]
distance_list = result['distances'][0]
relevant_values_array = np.column_stack((ids_list , document_list , distance_list))
df = pd.DataFrame( columns=['benchmark_id', 'name' ,'l2_distance'], data = relevant_values_array)
result = df.to_dict(orient='records')
return result
@tool('get_relevant_studentscoreentries')
def get_relevant_studentscoreentries(question:str):
"""
Retrieves relevant student score entries based on a specific question related to the PIRLS 2021 study.
Args:
question (str): The question string to query against the 'studentscoreentries' collection.
Returns:
list: A list of dictionaries, each containing 'code', 'name', and 'l2_distance' of relevant student score entries.
"""
huggingface_ef = embedding_functions.HuggingFaceEmbeddingFunction(
api_key=os.environ['HUGGINGFACE_TOKEN'],
model_name="sentence-transformers/all-MiniLM-L6-v2"
)
chroma_client = chromadb.PersistentClient(path="src/rag/collections/")
collection = chroma_client.get_collection(name='studentscoreentries', embedding_function=huggingface_ef)
result = collection.query(
query_texts=question,
n_results=5
)
document_list = result['documents'][0]
ids_list = result['ids'][0]
distance_list = result['distances'][0]
relevant_values_array = np.column_stack((ids_list , document_list , distance_list))
df = pd.DataFrame( columns=['code', 'name' ,'l2_distance'], data = relevant_values_array)
result = df.to_dict(orient='records')
return resultConclusion
In this post we saw two approaches of how enhance our agent system with semantic search in the database. While maintaining ( or increasing ) the quality of our answer we were able to reduce the LLM API cost avoiding unnecessary queries to explore the database.
I hope you find it useful. Happy coding!!
2 thoughts on “Enhancing Relational Database Agents with Retrieval Augmented Generation (RAG)”